TensorFlow学习历程-1
2017-03-22
从零开始学习TensorFlow
原创文章,转载请注明:转自Luozm's Blog本文记录一个几乎没用过Python的初学者强行上手TensorFlow的头疼经历。
1. 数据读写
由于我的数据集是.mat格式,需要首先导入才能进行处理。
1.1 scipy.io读取保存mat文件
- 读取文件
在Python中可以使用 scipy.io 中的函数
loadmat()读取mat文件,函数savemat()保存文件。import scipy.io as scio dataFile = 'E://data.mat' data = scio.loadmat(dataFile)注意,读取出来的data是字典格式,里面的数据矩阵是Numpy矩阵格式。
- 保存文件
将这里的data[‘A’]矩阵重新保存到一个新的文件dataNew.mat中:
dataNew = 'E://dataNew.mat' scio.savemat(dataNew, {'A':data['A']})注意:是以字典的形式保存。
1.2 h5py读取和保存HDF5文件
见我的另一篇博文:Python实战经历总结-1
1.3 TensorFlow读取数据
参考资料: Reading data 数据读取
TensorFlow程序读取数据一共有3种方法:
- 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
- 从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
- 预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
1.3.1 Feeding
TensorFlow的数据供给机制允许你在TensorFlow运算图中将数据注入到任一张量中。因此,python运算可以把数据直接设置到TensorFlow图中。
通过给run()或者eval()函数输入feed_dict参数, 可以启动运算过程。
with tf.Session():
input = tf.placeholder(tf.float32)
classifier = ...
print classifier.eval(feed_dict={input: my_python_preprocessing_fn()})
虽然你可以使用常量和变量来替换任何一个张量,但是最好的做法应该是使用placeholder op节点。设计placeholder节点的唯一的意图就是为了提供数据供给(feeding)的方法。placeholder节点被声明的时候是未初始化的,也不包含数据,如果没有为它供给数据, 则TensorFlow运算的时候会产生错误,所以千万不要忘了为placeholder提供数据。
可以在tensorflow/g3doc/tutorials/mnist/fully_connected_feed.py找到使用placeholder和MNIST训练的例子,MNIST tutorial也讲述了这一例子。
1.3.2 TFRecord和queue
参考:
当数据量比较大的时候,就不能够直接将数据加载进内存,这时我们就需要使用TFRecord直接从文件中读取数据。
TFRecords文件包含了tf.train.Example协议内存块(protocol buffer)(协议内存块包含了字段 Features)。我们可以写一段代码获取你的数据, 将数据填入到Example协议内存块(protocol buffer),将协议内存块序列化为一个字符串, 并且通过tf.python_io.TFRecordWriter写入到TFRecords文件。
从TFRecords文件中读取数据, 可以使用tf.TFRecordReader的tf.parse_single_example解析器。这个操作可以将Example协议内存块(protocol buffer)解析为tensor。
- 生成TFRecords文件
我们使用
tf.train.Example来定义我们要填入的数据格式,然后使用tf.python_io.TFRecordWriter来写入。def save_as_tfrecord(name, images, labels): """Converts a dataset to tfrecords.""" if len(images) != len(labels): raise ValueError('Images size %d does not match label size %d.' % (images.shape[0], len(labels))) file_name = name+'.tfrecords' print 'Writing: '+file_name with tf.python_io.TFRecordWriter(os.path.join(DATA_PATH, file_name)) as TFWriter: for index in range(len(images)): image_raw = images[index].tostring() example = tf.train.Example( features=tf.train.Features( feature={'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[labels[index]])), 'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_raw])) })) TFWriter.write(example.SerializeToString())在列表中有三种类型:
bytes_list,float_list,int64_list,分别对应三种tf.train的转换方式。
注意:如果List里面只有一个元素请使用[]。
- 使用queue读取 一旦生成了TFRecords文件,接下来就可以使用队列(queue)读取数据了。
一定要注意保存和读取的格式相同,不然可能不会报错,但是训练出问题(我之前就把float32和float64忘记了)
def load_from_tfrecords(name, batch_size, num_epochs):
file_name = name + '.tfrecords'
filename_queue = tf.train.string_input_producer(file_name)], num_epochs=num_epochs)
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue) # return filename and files
# Defaults are not specified since both keys are required.
features = tf.parse_single_example(
serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'image': tf.FixedLenFeature([], tf.string),
})
image = tf.decode_raw(features['image'], tf.float64)
image = tf.reshape(image, [Utils.bands, Utils.patch_size, Utils.patch_size])
label = tf.cast(features['label'], tf.int32)
# Shuffle the examples and collect them into batch_size batches.
# (Internally uses a RandomShuffleQueue.)
# We run this in two threads to avoid being a bottleneck.
'''
images, labels = tf.train.shuffle_batch(
[image, label], batch_size=batch_size, num_threads=4,
capacity=1000 + 3 * batch_size,
# Ensures a minimum amount of shuffling of examples.
min_after_dequeue=1000)
'''
images, labels = tf.train.batch(
[image, label], batch_size=batch_size, num_threads=4)
images = tf.cast(images, tf.float32)
images = tf.transpose(images, (0, 2, 3, 1))
return images, labels
使用tf.train.shuffle_batch可以乱序生成batch,capacity为队列中最大元素数,min_after_dequeue为最小数目,以确保乱序的效果。
之后我们可以在训练的时候这样使用:
with tf.Graph().as_default():
# Import training & test datasets from TFRecords
with tf.name_scope('Inputs'):
train_images, train_labels = load_from_tfrecords(
'Train', batch_size=Utils.batch_size,
num_epochs=Utils.max_steps)
# Generate placeholders for dropout
is_training = tf.placeholder(tf.bool, name='is-training')
LOGITS = models.cnn_2d(train_images, is_training)
LOSS = models.loss(LOGITS, train_labels)
TRAIN = models.training(LOSS, Utils.learning_rate)
# Initialize
with tf.name_scope('Initialize'):
INIT = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
with tf.Session() as sess:
# Run the Op to initialize the variables.
sess.run(INIT)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# Start the training loop.
for step in xrange(Utils.max_steps):
start_time = time.time()
sess.run(TRAIN, feed_dict={is_training: True})
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
注意初始化的时候一定要global和local同时进行。
也可以使用while语句到最大epochs时退出,如下:
try:
step = 0
while not coord.should_stop():
_, loss_value = sess.run([train_op, loss])
step += 1
except tf.errors.OutOfRangeError:
print('Done training for %d epochs, %d steps.' % (FLAGS.num_epochs, step))
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
2. TensorBoard
TensorBoard是TF的一款可视化工具,能够让我们更好的监控大型网络结构。
官方参考资料:
2.1 Bug fixed
我使用的系统是Ubuntu 16.04,TensorFlow 1.0,CUDA 8.0,cuDNN 5.1。可以正常使用TF以及TensorBoard的基本功能,但是如果使用TensorBoard来可视化内存和运行时间信息时,系统会报错:
I tensorflow/stream_executor/dso_loader.cc:126] Couldn't open CUDA library libcupti.so.8.0. LD_LIBRARY_PATH: :/usr/local/cuda/lib64
F tensorflow/core/platform/default/gpu/cupti_wrapper.cc:59] Check failed: ::tensorflow::Status::OK() == (::tensorflow::Env::Default()->GetSymbolFromLibrary( GetDsoHandle(), kName, &f)) (OK vs. Not found: /home/tom/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/_pywrap_tensorflow.so: undefined symbol: cuptiActivityRegisterCallbacks)could not find cuptiActivityRegisterCallbacksin libcupti DSO Aborted
如果遇到类似情况,请检查是否安装如下的包:
sudo apt-get install libcupti-dev
如果安装之后仍然报错,则是系统路径问题。请在LD_LIBRARY_PATH中添加路径: /usr/local/cuda/extras/CUPTI/lib64
添加方法: 修改~/.bashrc或~/.bash_profile或系统级别的/etc/profile
在其中添加:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
亲测有效。另外我对这个问题也不是特别明白,如果有疑问可以查阅:
2.2 使用TensorBoard
首先在运行TensorBoard之前,需要创建FileWriter来读取计算图中的信息(这行代码通常写在Session之后,Training loop之前):
# sess.graph contains the graph definition; that enables the Graph Visualizer.
file_writer = tf.summary.FileWriter('path/to/logs', sess.graph)
2.2.1 Summary操作
在TensorBoard中,数据通过Summary操作来记录数据,进行可视化。
Summary操作主要有:
- tf.summary.tensor_summary:用于记录模型中某一tensor的状态
- tf.summary.scalar:最常用的操作,用于记录模型中的标量(通常是loss或者eval值)
- tf.summary.histogram:用于记录某一tensor的变化(统计分布)
- tf.summary.audio:记录音频文件
- tf.summary.image:记录图像文件
- tf.summary.merge:合并对某一个tensor的所有记录,等待写入文件
- tf.summary.merge_all:最常用的操作,用于合并所有summary记录,等待写入文件
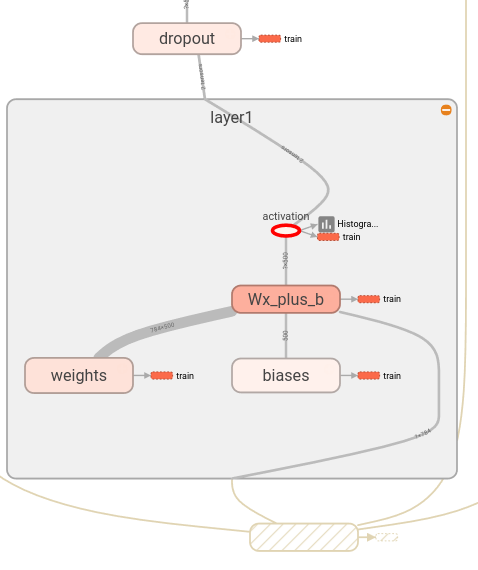
2.2.2 节点命名
使用with tf.name_scope()语句来给计算图中的任意操作命名,注意这个语句可以嵌套来描述结构化的操作。
示例:
with tf.name_scope('hidden') as scope:
a = tf.constant(5, name='alpha')
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0), name='weights')
b = tf.Variable(tf.zeros([1]), name='biases')
上述代码将三个语句共同命名为hidden,并给三个操作分别命名:
- hidden/alpha
- hidden/weights
- hidden/biases
此外,通常情况下,大部分TF的操作都默认有自己的名字,如果觉得层次比较清晰也可以不用自己命名。
2.2.3 示例代码
这里给出官网的一段示例代码以供参考:
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses relu to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# Adding a name scope ensures logical grouping of the layers in the graph.
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for the layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_activations', preactivate)
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
# Do not apply softmax activation yet, see below.
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
with tf.name_scope('cross_entropy'):
# The raw formulation of cross-entropy,
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the
# raw outputs of the nn_layer above, and then average across
# the batch.
diff = tf.nn.softmax_cross_entropy_with_logits(targets=y_, logits=y)
with tf.name_scope('total'):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(
cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# Merge all the summaries and write them out to /tmp/mnist_logs (by default)
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/train',
sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/test')
tf.global_variables_initializer().run()
2.2.4 自定义summary
当我们自己想添加其他数据到TensorBoard的时候(例如验证时的loss等),上面的方式显得太过繁琐,其实我们可以通过如下方式添加自定义数据到TensorBoard内显示:
summary = tf.Summary(value=[
tf.Summary.Value(tag="summary_tag", simple_value=0),
tf.Summary.Value(tag="summary_tag2", simple_value=1),
])
# x代表横轴坐标
summary_writer.add_summary(summary, x)
或者
summary = tf.Summary()
summary.value.add(tag="summary_tag", simple_value=0)
summary.value.add(tag="summary_tag2", simple_value=1)
# x代表横轴坐标
summary_writer.add_summary(summary, x)
注意,这里的x只能是整数,如果是小数的话会自动转为整数类型。
2.3 启动TensorBoard
在控制台使用如下代码启动TensorBoard:
tensorboard --logdir=path/to/log-directory
注意:其中的路径必须和FileWriter中的路径相同(第一个文件夹前不加“/”),否则可能会报错,即使实际指向的是同一个路径。(我在这一步卡了很久,上述方法亲测有效,但是还不确定是否必须。)
例如:
summary_writer = tf.summary.FileWriter(‘Graph’, sess.graph)
tensorboard --logdir Graph
经过上述的代码,打开TensorBoard之后我们应该能够看到生成的Scalars和Graphs,例如:
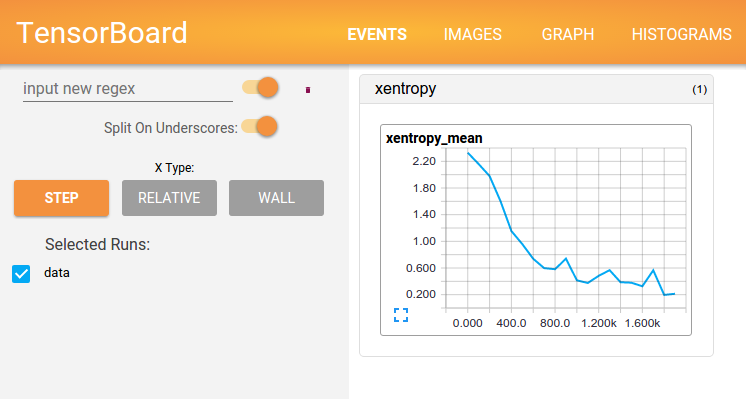
需要比较不同模型之间差异的时候,可以同时查看多次运行结果。在TensorBoard检查logdir时,它会自动将不同的文件夹视为不同的Runs,例如下面的目录可以生成run1和run2:
/some/path/mnist_experiments/
/some/path/mnist_experiments/run1/
/some/path/mnist_experiments/run1/events.out.tfevents.1456525581.name
/some/path/mnist_experiments/run1/events.out.tfevents.1456525585.name
/some/path/mnist_experiments/run2/
/some/path/mnist_experiments/run2/events.out.tfevents.1456525385.name
/tensorboard --logdir=/some/path/mnist_experiments
也可以使用逗号隔开不同的文件夹,以区分多次运行:
tensorboard --logdir=name1:/path/to/logs/1,name2:/path/to/logs/2
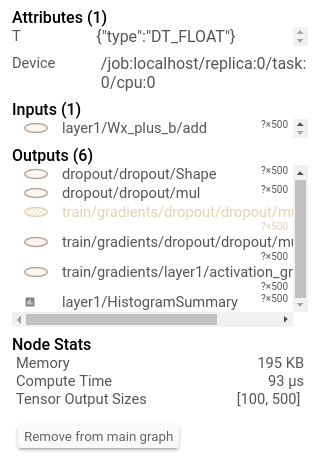
2.4 Runtime Statistics
当模型比较大的时候,我们想了解计算图中每一步骤的运行时间以及内存占用情况,这时仅仅记录上述操作就不够用了,需要记录metadata。
代码如下:(完整代码:mnist_with_summaries.py)
# Train the model, and also write summaries.
# Every 10th step, measure test-set accuracy, and write test summaries
# All other steps, run train_step on training data, & add training summaries
for i in range(FLAGS.max_steps):
if i % 10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # Record train set summaries, and train
if i % 100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
上述代码每100步在第99步时会生成运行时间和内存统计。
现在打开TensorBoard,可以选择Session runs,就可以查看相应的运行时间和内存了,例如: