基于深度学习的高光谱图像分类
2017-04-05
近期文献笔记总结:基于深度学习的高光谱图像分类
原创文章,转载请注明:转自Luozm's Blog一. Deep learning for remote sensing data (Review)
Zhang L, Zhang L, Du B. Deep learning for remote sensing data: A technical tutorial on the state of the art[J]. IEEE Geoscience and Remote Sensing Magazine, 2016, 4(2): 22-40.
1 基本框架
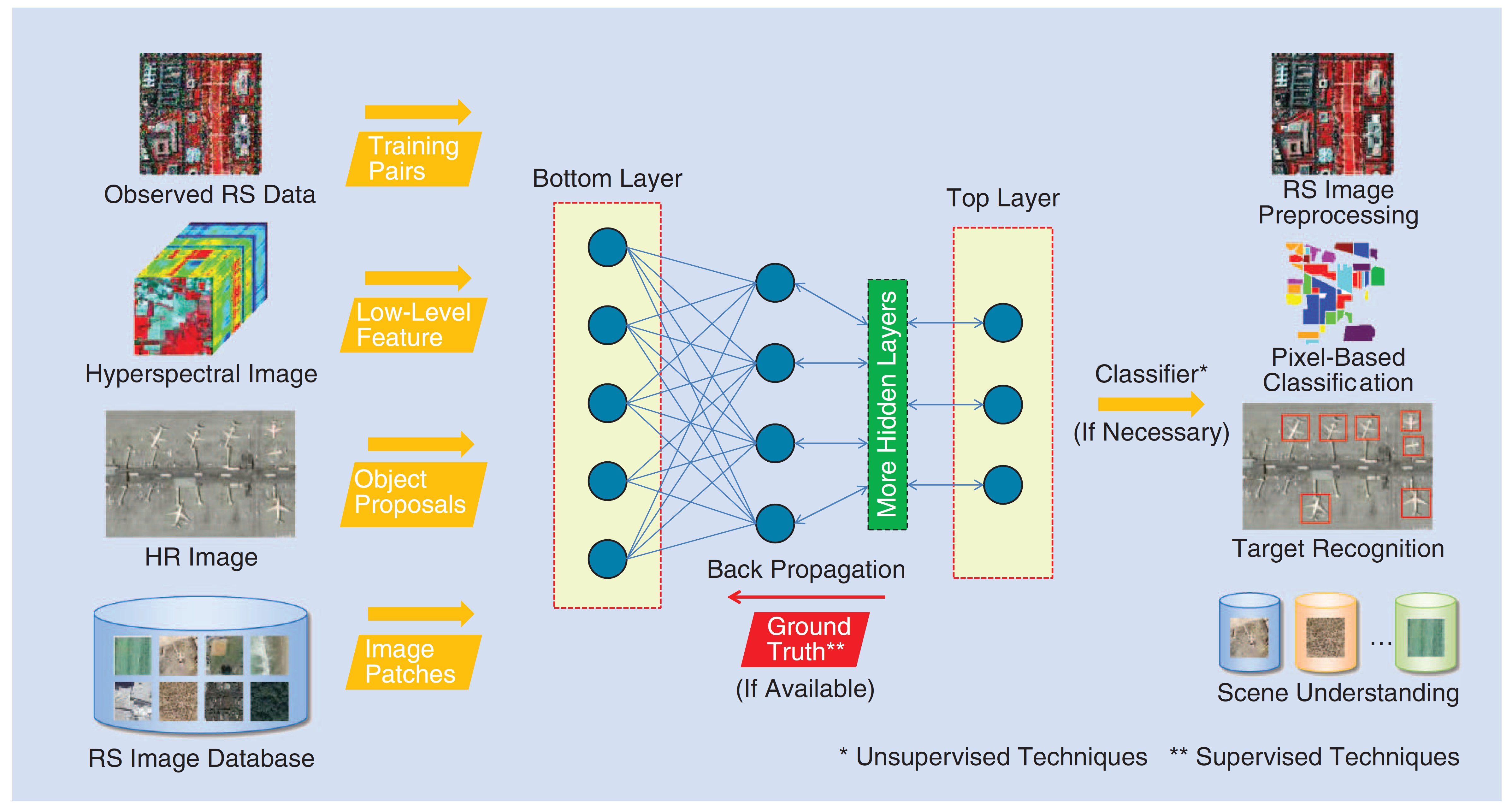
流程图包括三个主要组成部分:输入数据、核心深度网络和预期的输出数据。在实践中,输入输出数据对依赖于特定的应用。对于基于像素的分类,它们是光谱-空间特征及其特征表示(无监督学习)或标签信息(监督学习)。
确定输入输出数据对之后,输入和输出数据之间的关系,使用一个由多个级别的非线性操作组成的深度结构模型来构建,其中每层由一个浅层模型来建模。值得注意的是,如果有充足的训练样本可用,这样的深度网络就可以使用有监督的学习方法。
2 基础算法总结
深度信念网络(DBNs) 是深度学习研究的一个重大突破,是用受限玻尔兹曼机(RBMs)在一个无监督的情况下训练每个层。稍后,人们提出了一些基于 自动编码器(AE) 的算法,还提出了在每个级别局部训练表示的中间级别(即AE及其变体,例如SAE和DAE)。与AE不同,稀疏编码算法 通过自分解学习超完备字典,从不同的角度生成数据本身的稀疏表示。此外,作为最具代表性的有监督深度学习模型,卷积神经网络(CNN) 在视觉识别中的表现优于大多数算法。CNN的深层结构允许模型学习高度抽象的特征检测器,并将输入特征映射到能够明显提高后续分类器性能的表示。
2.1 CNN
2.2 AE
2.3 RBMs
2.4 Sparse Coding
3 具体应用
3.1 图像预处理
根据相关的遥感文献,大多数现有的遥感图像去噪、去模糊、超分辨率和Pan Sharpening的方法都是基于信号处理中的标准图像处理技术,而基于机器学习的方法很少。实际上,如果我们能够通过一组训练样本有效地模拟输入(观测数据)和输出(理想数据)之间的内在关联,则可以用同样的模型增强观测到的遥感图像。
恢复和去噪
对于遥感图像恢复和去噪,使用干净的图像训练网络模型,将原始图像输入到训练好的网络中获得恢复和去噪的图像。经典的反卷积网络模型是基于$L_1$正则化的图像卷积分解,其中$L_1$正则化是稀疏约束。在本研究进行的实验中,在深度网络中采用$L_{1/2}$正则化,给出了比$L_1$更稀疏的解,并取得了满意的结果。
Pan Sharpening
3.2 基于像素的分类
近年来,传统方法在手工特征描述、判别特征学习,分类器设计方面取得了显著进展。然而,从深度学习的角度来看,大多数现有方法只能提取原始数据的浅层特征,对于分类任务不够健壮。基于深度学习的遥感图像像素分类涉及到构建一个面向像素级的数据表示和分类的深度网络结构。采用深度学习技术,可以提取更健壮和抽象的特征表示,从而提高分类精度。
遥感图像像素级分类的方案包括三个主要步骤:
- 数据输入
- 分层深度学习模型训练
- 分类
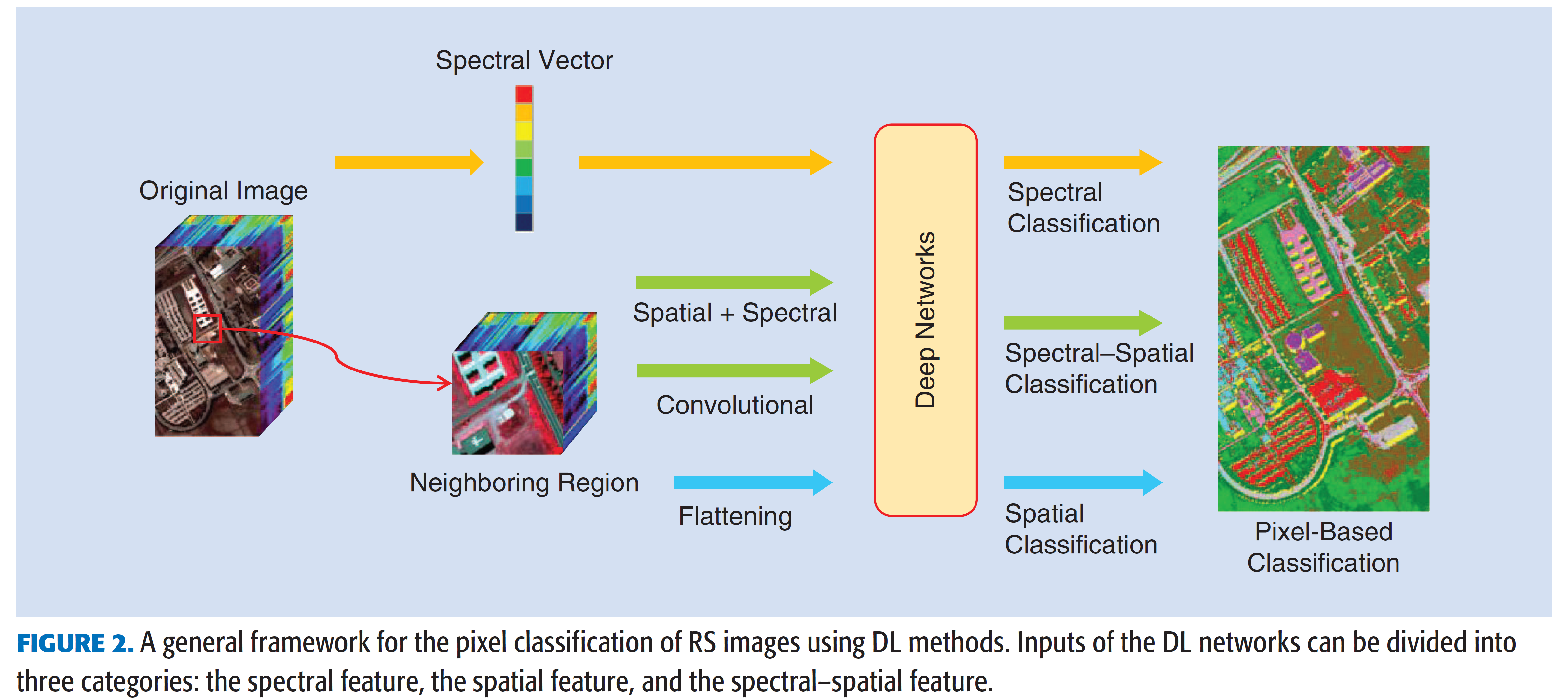
这个方案的一般流程图如图所示。在第一步中,输入向量可以是光谱特征、空间特征或光谱-空间特征。然后,对于隐藏层,设计一个深层网络结构来学习输入数据的特征表示。在相关文献中,有监督的深度学习结构(例如CNN)和无监督的深度学习结构(例如AE、DBN和其他在每层中自定义神经元的模型)。第三步是分类,通过在第二步(深度网络的顶层)中利用学习到的特征进行分类。通常,分类器主要有两种类型:
- 硬分类器(如支持向量机),它直接输出整数作为每个样本的类别;
- 软分类器(如逻辑回归),它可以同时微调整个预训练网络,以概率分布预测类别。
光谱特征分类
光谱信息通常含有丰富的判别信息。常用的遥感图像分类方法是基于光谱特征的分类方法。现有的常用的遥感图像分类方法大多是浅层的(如支持向量机和KNN)。相反,深度学习采用了一个深度的体系结构来处理原始数据和特定类别之间的复杂关系。对于光谱特征分类,原始图像数据的光谱特征直接作为输入向量。在网络部分训练输入向量,以获得稳健的深度特征表示,作为后续分类步骤的输入。选定的深层网络可以是CNN和AE。特别是林等人采用AE+SVM和SAE+逻辑回归作为网络结构和分类层,分别进行浅层和深度表征的分类任务。值得注意的是,由于更深的网络结构和参数微调步骤,深层光谱表示比浅层表示有更好的性能。
结合空间信息的分类
众所周知,在空间中土地覆盖是连续的,遥感图像中的相邻像素很可能属于同一类。如许多光谱-空间分类研究中所示,利用空间特征可以显著提高分类精度。然而,传统方法由于其自身的特点,无法提取稳健的深度特征表示。为了解决这个问题,提出了一些基于深度学习的特征学习方法,寻找一种提取深层光谱-空间表示的新方法。
对于原始遥感图像中的某个像素,自然要考虑其邻近像素来提取空间特征表示。然而,由于高光谱图像多达数百个的光谱波段,区域堆叠的特征向量会导致输入维数过大。因此,有必要在空间特征表示之前减少光谱特征维数。在第一步中,通常使用主成分分析(PCA),以便将数据维数减少到可接受的范围,并降低信息丢失。然后,在第二步中,通过使用原始图像中的每个特定像素的 $w×w$($w$ 是窗口的大小)邻域来收集空间信息。之后,将空间数据整理为一维向量,以输入深层网络。林等人和陈等人采用SAE作为深层网络结构。学习抽象特征之后,进行最终的分类步骤,类似于光谱分类方案。
在考虑联合光谱和空间特征提取和分类方案时,有两个主要策略来实现此目标。
- 直接地,不同于之前的光谱-空间分类方案,光谱和初始空间特征结合在一起成为一个向量作为深度学习网络的输入。相关论文选择的深层网络分别是SAE和DBN。然后,通过学习的深层网络,得到各个测试样本的联合光谱-空间特征表示,用于后续的分类任务,该分类任务与前面描述的光谱空间分类方案相同。
- 另一种方法是通过带卷积的深层网络处理某个像素的光谱和空间信息(例如CNN、CAE和特殊定义的深层网络)。
此外,还有一些分层学习框架,将每一步操作(例如,特征提取、分类和后处理)作为深层网络中的一层。
3.3 目标识别
3.4 场景理解
4 实验及分析
5 结论及展望
我们系统地回顾了遥感数据分析中的前沿技术。深度学习最初起源于机器学习领域,用于分类和识别任务,它们只是最近才出现在地球科学和遥感领域。从图像预处理、基于像素的分类、目标识别和场景理解四个角度,我们发现深度学习在目标识别和场景理解方面取得了显著的成功,这也正是在最近几十年中被遥感研究群体广泛认为是挑战的领域。因为这些应用要求我们从底层特征(通常为原始像素表示)提取高层语义信息,而传统的描述特征提取分类的遥感方法是浅层模型,难以或不可能揭示高层次的特征。
另一方面,在图像预处理和基于像素的分类中(特别是考虑大规模训练集的成本),深度学习的研究成果并不突出。部分原因是图像质量的提高更可能与图像退化模型(与传统方法一样)相关。在大多数情况下,即使只处理光谱特征,预测遥感图像的像素标签的任务是相对浅层的。尽管如此,我们坚信深度学习在遥感数据分析中是至关重要的,特别是对于遥感大数据的年龄而言。
然而,关于深度学习的研究仍然年轻,许多问题仍然没有答案。以下是一些遥感数据分析中潜在的有趣话题。
- 训练样本数量的缺乏:虽然深度学习方法可以从原始遥感图像中获取高度抽象的特征表示,但是检测和识别性能依赖于大量的训练样本。然而,由于收集带标记的高分辨率图像的困难,研究通常缺乏高质量的训练图像。在这种情况下,如何在较少的训练样本下保持深度学习方法的表征学习性能仍然是一个很大的挑战。
- 遥感图像的复杂性:与自然场景图像不同,高分辨率遥感图像包括不同大小、颜色、方向的物体,同时属于不同类别的不同场景在许多方面可能相似。遥感图像的复杂性使得从场景和对象中学习具有健壮性和区分性表示的难度大大增加。
- 数据集之间的传输:一个有趣的方向是从深度网络中学习的特征检测器从一个数据集向另一个数据集的传输,因为在某些遥感领域往往缺乏训练图像。特别是面对遥感数据集的巨大变化,问题可能更严重,这需要进一步的系统研究。
- 深度学习模型的深度:深度网络越深,这个模型的性能越好。对于有监督的网络(如CNN),更深的层可以学习更复杂的分布。但它们也可能导致有更多的参数需要学习,因此可能导致过拟合问题,特别是在训练样本不足时。计算时间也是应考虑的一个重要因素。给定数据集上的深度学习模型的最佳深度仍然是有待研究的课题。
二. BASS Net(Spectral-Spatial-CNN)
Santara A, Mani K, Hatwar P, et al. BASS Net: Band-Adaptive Spectral-Spatial Feature Learning Neural Network for Hyperspectral Image Classification[J]. arXiv preprint arXiv:1612.00144, 2016.
1 摘要
基于深度学习的土地覆盖分类算法最近已经在文献中被提出。在高光谱图像领域,他们面临着高维度、光谱特征的空间变异性与标记数据稀缺的挑战。在这篇文章中,我们提出一个端到端的深度学习结构,它提取波段特定的光谱-空间特征并进行土地覆盖分类。该结构使用更少的独立连接权重,因此需要较少的训练数据。该方法的性能在流行的高光谱图像数据集上的准确性优于最高值。
2 相关研究背景
2.1 挑战
- 大量的光谱维度导致的维数灾难;
- 标记训练样本的稀缺;
- 光谱特征的巨大空间变异性。
2.2 SVM通用步骤
- 降维以解决过高光谱维数和标记训练样本稀缺的问题,其中降维的方法有:子空间投影、随机特征选择和Kernel Local Fisher Discriminant Analysis(判别分析);
- 在降维后的空间使用SVM进行分类。
2.3 其他方法
- 局部Fisher判别分析降维+高斯混合模型(GMM)分类;
- 高斯非线性判别分析降维+相关向量机(Relevance Vector Machine)分类;
- (LBP+Gabor+光谱)特征提取+ELM分类;
2.4 深度学习方法
深度学习(深度神经网络)方法在高光谱图像分类上集中于光谱-空间特征关系建模来解决光谱特征空间变异性的问题。这些方法分为两类:
- 通过自动编码机(Autoencoder,AE)来降维和光谱-空间特征学习;使用多类逻辑回归来分类。
- 以端到端的方式使用CNN来进行特征学习和分类。CNN使用参数共享以解决维度灾难。
后续的CNN研究有:
- 将压缩的光谱特征(使用局部判别嵌入方法)和空间特征(从CNN得到)级联然后使用多类分类器分类;
- 使用端到端的CNN进行光谱-空间特征学习及分类;
- 利用CNN对像素对特征(pixel-pair)进行分类,弥补了标记训练数据的不足。还提出了一种表决策略,用于测试时间,以提供在异构区域的鲁棒性。
3 原理及算法
3.1 结构
本文提出了一种深层神经网络体系结构来学习特定波段的光谱-空间特征,其中没有任何形式的数据集扩增和输入预处理。
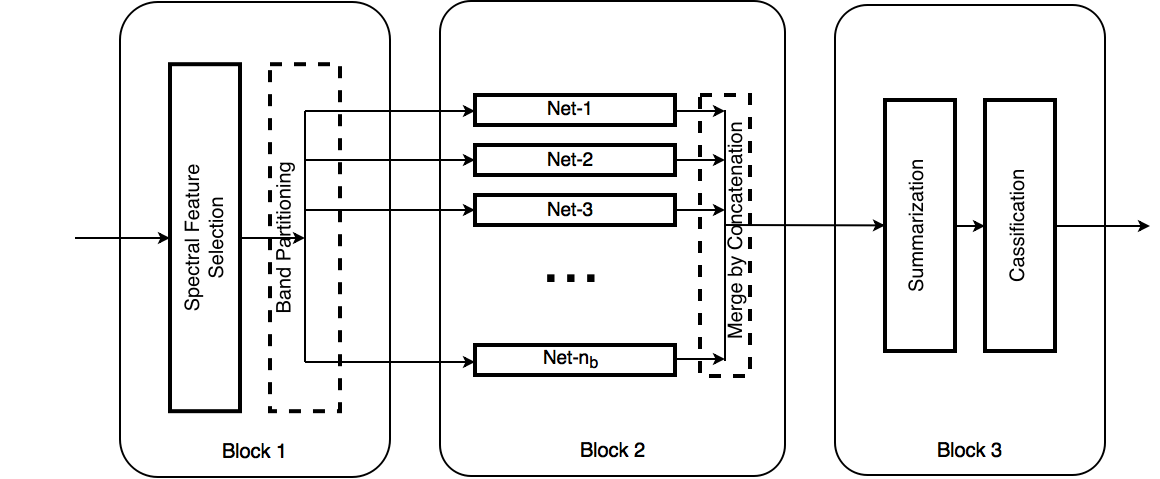
该结构由三个相连的模块组成。模块1输入 $p×p×N_c$($N_c$ 为光谱波段数)的数据,然后在光谱维度上进行初步的特征变换。它将光谱波段分成不同的段然后提供给模块2。模块2中的并行神经网络用于提取低级和中级的光谱-空间特征。将并行网络的输出连接融合,并提供给模块3,将它们总结为输入的高级表示形式。最终使用逻辑回归进行分类。
广泛使用卷积层和并行网络之间的权重共享保持参数数量和计算复杂性较低。特定波段的表示学习与模块2中的连接融合使得网络对于低级和中级特征的光谱局部性具有区分性。对基准高光谱图像分类数据集的实验表明,该网络收敛速度快,分类性能优于其他基于深度学习的方法。
3.2 贡献
- 提出了一种端到端的神经网络结构,并在常用数据集上表现出了极佳的性能。这种设计有效的特定波段特征学习使得 参数的数量较低;
- 与其他深度学习结构相比 训练时间的缩短方面有很大的提升。
4 实验结果
4.1 数据集
- Indian Pines:选择数量最多的9个类别
- Salinas:类别全选
- PaviaU:类别全选
每个类别随机选取200个标记的像素作为训练集,其余作为测试集。验证集是从用于调整模型超参数的可用训练集中提取的。输入值使用下式归一化到[0,1]区间:
4.2 结果
评价指标:
- 各类精度
- 总体精度
- Macro/Micro-averaged precision,recall,F值
- k值
| 结果 | Indian Pines | Salinas | PaviaU |
|---|---|---|---|
| OA | 96.77 | 95.36 | 97.48 |
| k | 96.12 | 94.80 | 96.62 |
5 结论及展望
本文提出了一种端到端的深度学习神经网络体系结构,用于对特定波段的光谱-空间特征进行学习建模。网络中广泛的参数共享解决了维数灾难和标记训练样本稀缺问题。根据目标像素周围的p×p邻域进行预测,以照顾高光谱图像中光谱特征的大空间变异性。对基准高光谱图像分类数据集的实验表明,该分类方法具有较高的分类性能和较快的收敛速度。
三. 3D CNN(Spectral-Spatial 3D CNN)
Li Y, Zhang H, Shen Q. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network[J]. Remote Sensing, 2017, 9(1): 67.
1 摘要
最近的研究表明,利用光谱-空间信息可以极大的提升高光谱图像(HSI)分类的性能。HSI数据通常以三维立方体的格式呈现。因此,三维空间滤波自然地提供了一种简单有效的方法,同时提取这些图像中的光谱-空间特征。本文提出了一种三维卷积神经网络(3D-CNN)框架用于准确的HSI分类。该方法整体观察HSI立方体数据集,而完全不依赖任何预处理或后期处理,有效地提取了联合光谱-空间特征。此外,它需要的参数比其他基于深度学习的方法更少。因此,该模型更轻,更不容易过拟合,更容易训练。为了比较和验证,我们测试了三种基于深度学习的方法——SAE、DBN和2D-CNN——基于不同传感器捕获的三个真实世界的HSI数据集。实验结果表明,基于3D-CNN的方法优于现有的同类方法,并创造了新的记录.
2 相关研究背景
3 原理及算法
3.1 三维卷积运算
2D-CNN在计算机视觉和图像处理领域得到了广泛的应用,如图像分类、目标检测以及单个图像的深度估计。2D-CNN最显著的优点是它提供了一种直接从原始输入图像提取特征的方法。然而,直接将2D-CNN应用于高光谱图像,需要对网络中每个二维输入进行卷积,每一个光谱波段都有一组需学习的核。沿着HSI的光谱波段(网络输入)的数百个通道需要大量的卷积核(需学习的参数),这可能在增加计算成本的同时也容易过度拟合。
为了解决这一问题,通常在使用二维神经网络进行特征提取和分类前,采用降维方法对数据进行降维。例如:
- 从HSI提取前三个主成分,然后利用2D-CNN从压缩的HSI数据中提取深度特征,窗口大小为42×42,以预测每个像素的标号。
- 引入了随机PCA(R-PCA),沿着光谱维度以压缩整个HSI数据集,保留前十个或30个主成分。然后使用2D-CNN从压缩的数据中提取深度特征(窗口大小为5×5),最后完成分类任务。
- 另一个方法有三个计算步骤:首先对整个HSI数据集使用PCA算法白化(whitened),只保留几个顶层的波段,接着通过2D-CNN提取高级特征;然后应用稀疏表示进一步降低第一步产生的高级空间特征的维数。最后得到基于学习的稀疏字典的分类结果。
这些方法的一个明显缺点是它们不能很好地保留光谱信息。
为了充分利用深度学习的特点,我们将3D-CNN引入到HSI处理中。3D-CNN使用三位的卷积核来进行三维卷积操作,可以同时提取空间特征和光谱特征。下图显示了二维卷积运算和三维卷积运算的关键区别。

在二维卷积运算中,在通过激活函数生成输出数据之前,输入数据通过二维卷积核来进行卷积。这个运算的公式如下:
其中 $l$ 表示运算所在的层,$j$ 是这层上特征映射的数目,$v_{lj}^{xy}$ 代表在 $l$ 层 $(x,y)$ 位置上的第 $j$ 个特征映射的输出,$b$ 是偏置,$f(\cdot)$ 是激活函数,$m$ 是连接到当前特征映射的 $(l-1)$ 层上的特征映射集合,而$k_{ljm}^{hw}$ 是连接到第 $j$ 个特征映射的核在 $(h,w)$ 位置上的输出,$H_l$ 和 $W_l$ 分别是核的高和宽。
在2D-CNN中,卷积运算是只能捕捉空间维度特征的二维特征映射。当其应用到三维数据时,人们希望能够同时从空间和时间维度捕捉特征。为了解决这个问题,提出了3D-CNN,其中三维卷积运算应用到三维特征立方体,以计算来自三维输入数据的时空特征。具体地,在第 $l$ 层中,$(x,y,z)$ 位置在第 $j$ 个特征立方体上的值如下:
其中 $R_l$ 是沿光谱维度的三维卷积核的大小,$j$ 是该层中的核数目,$k_{ljm}^{hwr}$ 是与前一层的第 $m$ 特征立方体连接的核的第 $(h,w,r)$ 个值。
在基于3D-CNN的分类模型中,每个特征立方体被独立处理。因此在上式中 $m=1$,三维卷积运算可以重新表示为:
其中 $D_l$ 是三维核的光谱深度,$i$ 是前一层特征立方体的数目,$j$ 是该层中核的数目,$v_{lij}^{xyz}$ 是利用前一层第 $i$ 个特征立方体与 $l$ 层第 $j$ 个核卷积计算得到的 $(x, y, z)$ 位置的输出,$k_{lj}^{hwd}$ 是与前一层第 $i$ 个特征立方体相连接的核的第 $(h,w,d)$ 个值。因此,第 $l$ 卷积层的输出数据包含 $i×j$ 三维特征立方体。
非饱和激活函数修正线性单元(ReLUs)是一种最流行的激活函数。特别是,在梯度下降的训练时间方面,ReLUs比其他饱和激活函数更快。这里我们采用ReLUs作为激活函数。其公式如下:
综上所述,对于HSI分类,二维卷积运算将输入数据在空间维度上卷积,而三维卷积运算同时在空间维度和光谱维度上对输入数据进行卷积。对于二维卷积运算,无论它应用于二维数据或三维数据,其输出是二维的。如果将二维卷积运算应用于HSI,将会丢失大量的光谱信息,而三维卷积则可以保留输入数据的光谱信息,从而产生三维输出。这对于含有丰富光谱信息的HSI是非常重要的。
3.2 3D-CNN-Based HSI Classification
传统的2D-CNN通常由卷积层、池化层和全连通层组成。与2D-CNN不同,用于HSI分类的3D-CNN仅由卷积层和全连通层组成。我们不采用池化操作,池化是为了减少HSI的空间分辨率。与图像级分类模型相比,我们的3D-CNN模型用于像素级的HSI分类。它沿着所有光谱波段提取了一个小空间邻域(不是整个图像)的像素组成的图像立方体作为输入数据,通过三维卷积核来卷积,以学习光谱-空间特征。因此,池化操作进一步减少了特征映射的分辨率。利用相邻像素的原因是,一个小空间邻域内的像素经常反映相同的内在材料(与马尔可夫随机场所采用的平滑假设一样)。
提出的3D-CNN模型含有两个三维卷积层(C1和C2)和一个全连接层(F1)。根据2D-CNN的结果,具有较深结构的3×3卷积核的小感受野通常会产生更好的结果。Tran等人还证明了小3×3×3核是3D-CNN在时空特征学习中的最佳选择。受此启发,我们将三维卷积核的空间大小固定到3×3,而只稍稍改变了核的光谱深度。卷积层数受输入样本空间大小的限制,其中窗口根据经验设置为5×5。执行两次卷积运算,空间大小为3×3,将样本的大小减少到1×1。因此,提出的3D-CNN仅包含两个卷积层就足够了。此外,第二卷积层的核数目设置为第一卷积层的两倍。这种比率通常被许多CNN模型所采用。输入数据在每个三维卷积层上使用所学的三维核来卷积;然后通过选定的激活函数计算卷积结果。F1层的输出被送到简单线性分类器(例如softmax)以生成所需的分类结果。请注意,网络使用标准反向传播(BP)算法进行训练。本文以softmax loss作为训练分类器的损失函数。因此,该框架被命名为3D-CNN。在本节中,我们详细解释如何使用3D-CNN有效和高效地对HSI数据进行分类。

为了对像素进行分类,使用3D-CNN模型提取像素的相关信息。上图概述了计算过程。为了说明,我们将3D-CNN分为三个步骤:
-
训练样本提取:$S×S×L$ 图像立方体与这些立方体中心像素的分类标签一起提取作为训练样本。$S×S$ 是空间大小(窗口大小),$L$ 表示光谱波段的数量。
-
基于3D-CNN的光谱-空间特征提取:输入数据的样本大小为 $S×S×L$。第一卷积层C1包含两个三维卷积核,每个大小为 $K_1^1×K_2^1×K_3^1$ 的卷积核产生大小为 $(S-K_1^1+1)×(S-K_2^1+1)×(L-K_3^1+1)$ 的三维数据立方体(根据之前的三维卷积公式)。每个三维卷积核产生一个三维数据立方体。使用第一卷积层输出的这两个三维数据立方体作为输入,第二卷积层C2包含四个三维卷积核(大小为 $K_1^2×K_2^2×K_3^2$),产生8个大小为 $(S-K_1^1-K_1^2+2)×(S-K_2^1-K_2^2+2)×(L-K_3^1-K_3^2+1)$ 的三维数据立方体。8个三维数据立方体被压扁成一个特征向量,并向前输入到全连接层F1,其输出特征向量(图中命名为特征3)包含最终习得的深层光谱-空间特征。
-
基于深度光谱-空间特征的分类:我们使用softmax loss来训练深层分类器。与二维的情况一样,利用反向传播的随机梯度下降最小化网络的损失。卷积核更新为:
| 其中 $i$ 是迭代次数,$m$ 是动量(momentum)变量,$\varepsilon$ 是学习率,$\langle\frac{\partial L}{\partial w} | {w_i}\rangle{D_i}$ 是第$i$ 批 $D_i$ 中目标函数对 $w$ 导数的均值,$w$ 是3D-CNN的参数,包括三维卷积核以及偏置。 |
3.3 Feature Analysis
特征分析对于理解深度学习机制是非常重要的。在本节中,我们说明了3D-CNN模型提取的特征。以PaviaU数据集为例,学习到的特征根据不同的3D-CNN中的层展示出来。
PaviaU场景包含103个波段。从原始HSI中提取一个大小为50×50×103的数据立方体,然后从这个数据立方体中随机选择四个波段展示在下图a中。在第一个卷积层的三维卷积运算后,这个数据立方体被转化为两个数据立方体,每个空间大小为48×48,每个立方体选择8个波段展示在下图b中。使用第一卷积层的输出作为第二卷积层的输入,我们从第二个卷积层的输出中提取8个波段展示在下图c中。合起来,下图中的特征图像说明了下列几点:
- 不同的对象类型激活不同的特征图像。例如,图c中的8个特征图像基本上由8个不同的内容激活。
- 不同层次编码不同的特征类型。在更高层次,计算的特征更抽象更具区分性。

通常情况下,产生的特征图像的数量可能非常庞大,一个特征图像可以看作输入图像的一个高级表示。一个特定的表示很难完全捕捉内在的图像信息,所以表示图像通常需要大量的特征图像。
4 数据及实验
4.1 数据集
- PaviaU:610×340×103(41849),随机50%训练集,50%测试集;
- Botswana:1476×256×145(3248),随机50%训练集,50%测试集;
- Indian Pines:145×145×200(10086),随机50%训练集,50%测试集。
4.2 实验设置
为了评价的模型有效性,我们用3D-CNN与三个深度学习模型进行比较:SAE-LR、DBN-LR以及2D-CNN。使用整体精度(OA)、平均精度(AA)、Kappa系数(K)作为分类性能指标。为了获得更有说服力的模型能力估计,我们对每个数据集重复进行10次实验。每次,重新随机抽样数据平分生成训练集和测试集。
4.3 实验结果
5 结论及展望
本文为了改进HSI分类,提出了一种新的3D-CNN分类框架,充分利用了HSI数据中包含的光谱和空间信息。结果表明,3D-CNN模型可以适应HSI的三维结构进行分类。特别是,我们对基于三种常用的HSI基准数据集的三种基于深度学习的HSI分类方法进行了比较。实验研究表明,基于三维神经网络的HSI分类方法在所有三个数据集上达到了最佳的综合精度。它具有捕获局部三维模式的潜力,有助于提高分类性能。
在未来的研究中,我们计划研究更有效的可以利用无标记样本的基于3D-CNN的分类技术。在HSI数据集中,未标记样本比标记样本更容易获得。基于3D-CNN的监督分类方法不能充分利用这些未标注样本。为了更好地解决这一问题,一种基于3D-CNN的整合无监督和半监督的分类方法可能更加合适。
四. FCN in Aerial Images
Marmanis D, Wegner J D, Galliani S, et al. Semantic Segmentation of Aerial Images with an Ensemble of CNSS[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2016, 2016, 3: 473-480.
1 摘要
2 相关研究背景
3 原理及算法
4 实验结果
本文以摄影测量学会二维语义标注比赛的Vaihingen数据集为例,对该方法进行了实证检验。它包括大小不同的33个tiles(?),从一个有三个光谱带(红色、绿色、近红外线)的空中正射影像拼接,加上同一分辨率的数字表面模型(DSM)。该数据集总共包含大约1.7×10^8个像素,但真实值只包含了一半的tiles,用于训练和验证。其余部分则保留对模型的结果进行客观评价。图像细节丰富,GSD为9厘米。分类的类别包括不透光的表面、建筑物、低矮的植被、树木和汽车。为了使我们的pipeline自动达到尽可能大的程度,我们不使用需要人工干预或选择数据特定的超级参数(例如需求侧管理滤波或辐射校正)的任何预处理,而是将标准提供的数据直接输入网络。
我们实验的细节是,我们将真实值已知的16张图片(tiles)切分为训练子集,然后将保留标签的子集用于测试。我们从训练集中随机抽样12000个259259像素的像素块来学习FCN参数。请注意,在测试时,网络每次输出一个259259像素的像素块的完整标签。为了预测整个tiles的标签,我们平均每个重叠像素的类别得分。
4.1 训练细节
低级特征例如边缘和颜色在不同图像之间不会有显著的改变,但是捕捉更大形状和模式的高级特征更加随任务而定。因此在保持较浅的层固定的同时首先训练更深的层是有意义的。我们首先训练在全卷积层之上的所有层(见图2),迭代40,000次,然后再进行50,000次的整体模型训练。实验表明,后者只是略微提高了性能(总体精度提升<1%),这表明低层的滤波器的权重确实从近距离图像推广到遥感图像。对于学习速率的选择,通常做法是以合理的较快学习速度开始,并在训练期间不断减少。这样,在开始时,当它仍然远离一个好的解决方案时网络学得更快,但在结束微调时没有过度。我们的学习率从10^-9开始,然后每20,000次减少10倍。
每次训练迭代由一次前馈传播,一次预测值和真实标签值的比较和一次反向传播步骤(通过SGD调整网络权重)组成。前馈步骤只需要矩阵乘法,比每个权重的梯度都需要评估的反向传播的代价低很多。
另一个好用的技巧是在训练期间使用dropout,即通过随机切断部分神经元的连接来减少过拟合。我们对两个较深的层使用50%的dropout率。实验表明,在训练中dropout在我们的实验中只能提高很少的性能。我们将其归因于两个原因。第一,我们从已经在大型数据集上精心预训练过(使用dropout)的模型开始。浅层对于我们的训练集进行微调,但是没有剧烈的改变初始的正则化过的状态,所以过拟合不是问题。
5 结论及展望
五. SDAE(Spectral-Spatial Deep Auto-Encoder)
Ma X, Wang H, Geng J. Spectral–spatial classification of hyperspectral image based on deep auto-encoder[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2016, 9(9): 4073-4085.
1. 摘要
本文主要关注如何在HSI分类框架中提取和利用深层特征。首先,为了提取光谱-空间信息,本文提出了一种改进的空间更新自编码器(SDAE)。它通过在能量函数中添加一个正则化项来考虑样本的相似度,然后通过整合上下文信息来更新特征。其次,为了解决在小训练集上使用深层特征的问题,应用了一种基于协同表示(Collaborative Representation,CR)的分类方法。接着,为了抑制椒盐噪声(salt-and-pepper noise)并平滑结果,我们计算了所有样本协同表示的残差作为一个残差矩阵,它能够有效的使用在基于图割算法(graph-cut)的空间正则化中。提出的方法继承了深度学习的优势,并提出了在学习网络中增加HSI空间信息的解决方案。使用具有深度特征的协同表示分类使得所提出的分类器在小训练集下非常强大。大量的实验表明,与一些相关技术相比,所提出的方法提供了令人鼓舞的结果。
2 相关研究背景
近些年来,许多光谱-空间分类方法被提出。
- 大部分方法在分类之前提取空间特征,EMAP、tensor-based spectral–spatial features、composite kernels、multiple kernels、learning-based features。这种预处理方式来提取空间信息可以与任意分类器结合。
- 还有许多光谱-空间分类方法在分类同时利用空间信息,比如MRF、joint sparsity model、simultaneous subspace pursuit、nearest regularized。
- 有一些光谱-空间分类方法在基于像素的分类之后考虑空间平滑性,比如使用分割图来正则化基于像素的分类结果。
在HSI分类中,特征表示与分类器设计一样重要。在HSI中有三种特征表示类型:
- 特征选择(FS):FS基于一些规则在输入数据中寻找一个合适的子集,比如Jeffries-Matusita (J-M) distance、mutual information。
- 特征提取(FE):FE开发了一些转换,通常将完整的原始测量转换为新的子空间,比如PCA、minimum noise fraction (MNF)。
- 混合方法:在特征提取中同时使用FS和FE,比如先基于专家经验选择一些波段,然后在选定的波段上对其进行特征提取。
- 除了光谱特征和空间特征外,我们还可以获得HSI分类任务的其他信息,甚至可以从其他遥感数据获得一些信息,如高度信息。
可以处理高维度的HSI且促进分类结果的优秀的特征表征方法是必要的。然而,所有这些功能都是人工设计的,它利用了人类的聪明才智和先验知识。一些特征伴随着无法管理的参数,这些参数需要经验丰富的算子的交互。 此外,对于具体应用来说,并非所有特征都有效。成功应用于人工智能的深度学习,能够学习如何通过分层训练过程来表征特征,并可以通过最小化来自不同类的所有样本的均方误差来改进模型。层次结构类似于人类大脑的识别过程,它拥有比硬编码特征表征方法更好的抽象概念的学习能力。

3 原理及算法
首先,我们提出一个有监督的特征提取器:空间更新自编码器(SDAE),来联合利用HSI的光谱和空间特征。SDAE在特征学习阶段考虑邻域信息,最大化类之间的特征差异,这被认为更适合于HSI分类。此外,为了更好地利用深层特征,我们在特征空间中采用了基于协同表示(CR)的分类方法来获得结果。此外,为了抑制椒盐噪声,并平滑结果,我们利用基于协同表示的分类来得到一个残差矩阵,它可以被用于一种基于图割算法的空间正则化方法,该方法在小训练集下具有很强的鲁棒性。
3.1 SDAE
在特征提取中有两个事实需要考虑:(1)相似光谱特征的样本应该大概率的具有相同的类别标签,这是全局约束;(2)具有类似光谱特征的相邻样本也应大概率的拥有相同的类别标签,这是局部约束。
自编码器独立考虑每个样本,仅仅关注输入和重构之间的误差。为了使特征学习结构与全局约束相一致,我们改进DAE来保留样本之间的相关性。
我们通过添加一个由权重控制的相似度正则化项来改进自编码器中的能量函数,使之能够在我们的SDAE中使用。
其中权重 $\gamma(m,n)$ 是样本间的余弦相似度,$h^{(m)}$ 是样本 $x{(m)}$ 经自编码器编码后的结果,$\tilde{x}^{(m)}$ 是重构后的样本。
为了与局部约束相一致,我们在隐含层之后插入一个特征更新层。我们通过将每个特征替换为周围样本的加权平均值来实现空间平滑的隐含特征。假设 $N(x)$ 是一块以 $x$ 为中心的空间相邻像素块,特征更新公式如下:
其中上下文权重为:
3.2 基于协同表示的分类和空间正则化
为了解决小样本量的问题,我们采用一种在深层特征空间中的基于表示的分类器。当训练集不够大时,基于统计学习的分类器就不能够学习类别分布。然而,在协同表示中,每个测试样本可以被相同类别中最小残差的训练样本来线性表示。对于分类来说,每个样本的特征可以通过每个类内所有训练样本特征的线性组合来近似,并且类别标签可以认为是最接近于测试特征的类别。
第 $k$ 类别的训练集记为 $X_k$,它的每列都是属于 $k$ 类的一个样本。假设我们总共有 $K$ 类,训练集记为 $X=[X_1,X_2,\dots,X_K]\in\mathbb R^{N×M}$ ,其中 $M=\sum_{k=1}^K col(X_k)$ 是训练样本总数,$N$ 为样本的维度。一个测试样本 $x\in\mathbb R^N$ 可以被表示为:
其中 $\alpha=[\alpha_1,\alpha_2,\dots,\alpha_K]$,$\alpha_k$ 是与类别 $k$ 关联的表示向量。如果 $x$ 属于 $k$ 类,$x=X_k\alpha_k$ 应该具有最佳表示的最大值。
要点是,表示是在整个训练集 $X$ 中协同进行的,而不是分别在每个类的子训练集 $X_k$ 中进行。有几种最佳表示的定义,例如稀疏表示,除 $\alpha_k$ 外,$\alpha$ 中的系数几乎为零。
同样,在我们的框架中,对于训练集 $X$ 和测试样本 $x$,我们可以提取训练集的特征 $H$,测试样本的特征 $h$。在特征空间中,根据协同表示的思想,测试特征 $h$ 可以通过训练特征 $H$ 的线性组合逼近,测试样本 $x\in\mathbb R^{n_0}$ 的特征 $h\in\mathbb R^{n_L}$,其中 $n_L$ 是特征的维度,可以被写成所有训练像素的线性组合:
其中 $H=[H_1,H_2,\dots,H_K]$ 是由所有训练特征扩展的空间,$\beta$ 是表示向量。
假设最佳表示是稀疏的,$\beta$ 可由下列方程解出:
其中 $\rho$ 是稀疏正则化项的权重。这是一种经典的基于稀疏表示的分类,可以由一些L1最小化方法解出:梯度投影,iterative shrinkage-thresholding,augmented Lagrange multiplier (ALM)。
假设最佳表示有正则最小平方,$\beta$ 可由下列问题解出:
其中 $\eta$ 是正则化项的权重。这个方程有简单的解析解:
如果我们令
它与测试特征 $h$ 独立,这意味着我们可以通过将测试样本投影到 $P$ 得到其类别。因此,这个分类的计算代价很低。
此外,椒盐噪声在分类任务中是一个严重的问题。为了抑制椒盐噪声并平滑结果,我们改进了协同表示分类方法。空间正则化是一种广泛使用的平滑方法,为了使用基于图割的空间正则化,我们改进协同表示分类方法来获得每个样本的概率向量。在由上面的方程解出 $\beta$ 之后,我们计算每个类别中表示的残差:
其中 $k=1,\dots,K$,对于样本 $x$ 我们可以得到一个残差向量 $\varepsilon=(\varepsilon_1,\dots,\varepsilon_K)^T$。最小最大标准化用来将残差向量归一化到[0,1]区间,然后从一个全一向量中减去它。我们计算所有样本的残差向量来得到残差矩阵 $M\in\mathbb R^{C×R×K}$,其中 $C,R$ 分别是HSI数据集的长度和宽度。为了在结果图中添加空间信息并且去除噪声,我们使用图割来正则化分类的残差矩阵。通过平滑约束,图割算法成功应用于图像分割中。在这里,我们将残差矩阵视为后验概率,假设给定的特征的条件独立性,在等概率类别的假设下,spatial regurgitation可以看作最大后验概率(MAP)分割问题。